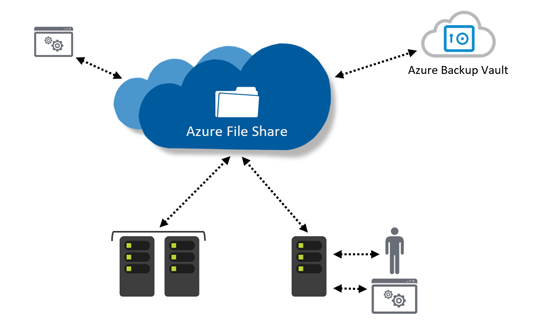
Tracing aplikacji w środowisku Microsoft Windows (.NET)
Dużo się teraz mówi o Observability, czyli rozszerzonym monitoringu, w którym poza pilnowaniem logów tekstowych i metryk, obserwujemy również co dzieje się wew. aplikacji. Większość materiałów na ten temat skupia się na rozbudowie narzędzi z perspektywy programisty, ja bym chciał podejść do tematu ściśle od strony administracyjnej i utrzymaniowej (bez dotykania kodu aplikacji).