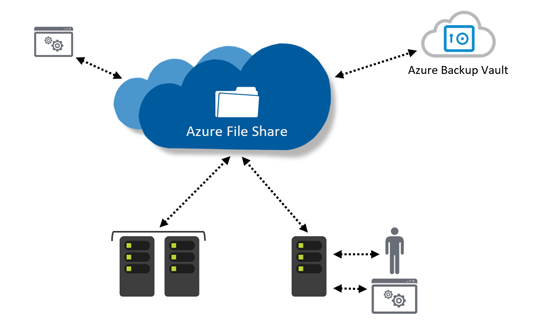
Azure File Sync – panaceum na Ransomware
Ataki ransomware są coraz częstsze i warto pomyśleć o jakiejś formie kolejnego miejsca na backupy, które będzie naszym zabezpieczeniem na wypadek ataku tego typu. Azure File Sync wraz z obsługą snapshotów może nam ten problem rozwiązać. Szczególnie że od strony użytkownika/administratora jest to bardzo przyjemne rozwiązanie.