Jak wycisnąć jak najwięcej mając licencję PRO w Microsoft Power BI? Poniżej kilka moich przemyśleń po wielu próbach znalezienia najlepszego podejścia do przetwarzania danych z użyciem Power BI.
Dlaczego Power BI i co było wcześniej?
Jak pewnie mało kto, nie korzystam z Power BI w celu realizacji analizy danych dla biznesu. Power BI ma wartość dodaną tylko i wyłącznie dla mnie. No i może zespół czasami coś z tego skorzysta, przy okazji.
Pomysł na wykorzystanie Power BI jest ewolucję wielu innych prób i testów. Bazowo mam środowisko monitorowane przez System Center Operations Manager (SCOM). Przy rosnącej skali sama konsola SCOMa nie nadaje się do analizy wydajności serwerów, brak możliwości agregacji danych w sensowny dla mnie sposób.
Reporting Services to jeden ze składników które można połączyć ze SCOMem i agregować dane. Ale nie jest łatwo tworzyć takie raporty.
Kolejnym pomysłem był Excel i Power View. Nawet działało, ale wolno i mając plik Excela o wielkości 200-300 MB, problemem był czas ładowania danych. Za każdym razem jak chciałem nowsze dane, musiałem ręcznie zainicjować pobieranie ich i czekać nawet do godziny.
Po drodze w SCOMie pojawiła się konsola web napisana w HTML 5, która umożliwiła wykorzystanie widgetów napisanych w JavaScript. Nawet nietrudno dało się to ogarnąć, ale ograniczeniem było pobieranie maksymalnie 200 instancji metryk. Czyli dla przykładu jak miałem 40 serwerów, każdy po 24 procesory logiczne, to żeby analizować z nich dane potrzebowałem załadować 960 metryk.
I wtedy cały na biało wchodzi Power BI. To taki Excel w ładnej szacie graficznej i z wyeksponowanymi narzędziami do analizy danych. Pod spodem budujemy kostkę analityczną, więc jak ktoś ma doświadczenie z budowaniem hurtowni danych to jest już w domu. Jak ktoś nie ma takiego doświadczenia, to Power BI jest na pewno najłatwiejszą drogę wejścia w te rozwiązania.
Jak i gdzie przepływają dane?
SCOM ma pod spodem bazę MSSQL i to do niej się odwołuję. Żeby budować zrozumiałe wykresy obciążenia serwerów/usług, posiłkuję się również dodatkowymi danymi z innej bazy MSSQL oraz kilku plików JSON (które opisują połączenia z niepowiązanych ze sobą systemów). Po stronie Power BI mieszam tymi danymi i tworzę relacje tam gdzie potrzebuję, tak by połączyć usługi z przynależnymi im metrykami. W ten sposób niezależnie jak serwery rotują i się zmieniają, w Power BI mam zawsze aktualne przyporządkowanie.
Power BI leży w Azure, więc nie ma dostępu do żadnym z moich źródeł danych. Pośrednikiem jest Power BI Gateway (a nawet dwa żeby mieć wysoką niezawodność), który ma dostęp do danych, a przy okazji wykonuje część przetwarzania/grupowania.
Z powyższej bramy dane wpadają do wielu obiektów typu Dataflow. Każdy Dataflow zbiera metryki jednego rodzaju (które da się w ten sam sposób przetworzyć). Mam ich kilka(naście), bo inaczej przetwarzam dane o obciążeniu CPU, a inaczej ilość żądań do IISa czy ilość Batch Requestów do SQLi.
Kolejnym krokiem jest zbiorczy model danych (Dataset), który zbiera ponownie dane z większości Dataflowów. To jest moje źródło prawdy dla raportów. Tu też mogę ustawić uprawnienia, z granulacją do takiego stopnia, że mogę dać komuś widok tylko do jednej aplikacji lub serwera – Row Level Security (reszty danych nie zobaczy w raportach). Datasetów mam kilka, np. dla danych bieżących (ostatnie 16 godzin), oraz dla danych archiwalnych (ostatni 60 dni). Osobno trzymam dane dla maszyn fizycznych i wirtualnych, bo do innych celów analizuję ich metryki.
Przepływ wygląda następująco: MSSQL, Json -> Power BI Gateway -> Dataflow -> Dataset -> Report
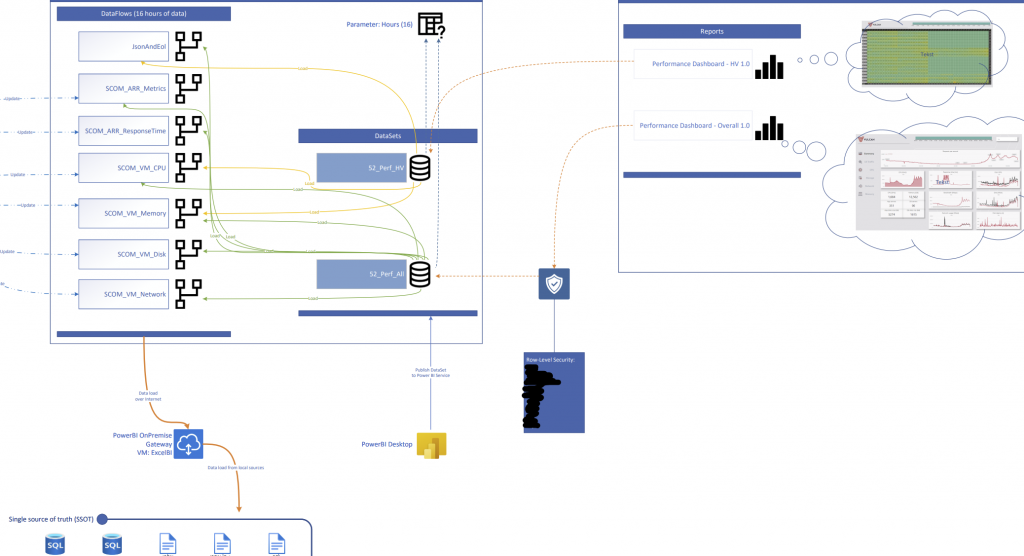
Dlaczego po drodze jest Dataflow?
Dataset i Dataflow w wielu przypadkach mogą robić dokładnie to samo. Ładują dane i odpowiednio je przetwarzają lub agregują (przeliczają np. bajty na megabity).
Tu dochodzimy do ograniczeń licencji PRO. Możemy odświeżać dane 8 razy dziennie i dzieje się to na ograniczonych zasobach chmury (co tylko się da ustawiam by wykonywało się na Gateway’u, bo tam mogę dać dużo CPU). W przypadku ładowania wszystkich danych od razu do Datasetu, szybko wpadłem na timeouty po stronie PowerBI, a dane bardzo wolno się „ładowały” (no bo jak coś trwa ponad godzinę dla bieżących danych to jest wolno).
Dataflow dzieli te dane na małe porcje, które mogą być przetwarzane w tym samym czasie (na ile źródła danych i Gateway’a nie dobijemy). Wstępnie zaciągnięte i zagregowane dane dużo szybciej da się połączyć w docelowy Dataset i to jest spora oszczędność czasu. Dużo łatwiej jest również rozbudowywać to rozwiązanie przez dołączanie kolejnych Dataflowów.
Dlaczego nie agregować po stronie SQLa?
Prawie na każdej prezentacji z Power BI mówi się, żeby filtrować i agregować ile tylko się da po stronie źródła danych. Ba, MSSQL całkiem dobrze sobie radzi z danymi i ich zwracaniem w różnych formach.
Tylko każdy CPU dla SQLa to konkretne pieniądze w licencjach SQL, a Gateway jest za darmo i możemy mu dać jakie tylko zasoby mamy w posiadaniu. Za przetwarzanie po stronie chmury też nie płacimy (poza czekaniem w kolejce na zasoby).
W praktyce z bazy MSSQL ładuję tylko bardzo podstawowe dane, najlepiej jak jedno zapytanie to jeden konkretny index/tabela w bazie (bez joinów, agregacji, itd.). W wielu przypadkach Query Folding po stronie Power BI zapewnia filtrowanie, dzięki czemu o mniej danych odpytujemy bazę.
Za wstępne przygotowanie danych odpowiada Dataflow (który wykonuje operacje na Gateway’ach). Jak jest dużo Dataflowów to generowane przez nie obciążenie dobrze rozkłada się na wiele instancji bram usługi Power BI.
Dataflow musi mieć jakieś ograniczenia, co nie?
Dla mnie jest jedno. Ładując dane bezpośrednio do Datasetu możemy skorzystać z Incremental Refresh (ładować tylko najnowsze dane, bez utraty tych wcześniej załadowanych). W Dataflow by działał Incremental Refresh potrzebujemy licencji Premium.
Podsumowanie
To jeszcze nie koniec wyciskania cytryny, w kolejnym wpisie będzie o Power Automate.